Imagine you are trying to explain to someone what Linear Regression is - but they have no programming/maths experience? How would you explain the overall process, what R-Squared means and how to interpret the coefficients?
This is my most favourite question on a first date. Linear regression is a modelling technique that explores potential relationships between variables. This could be between height and weight, number of viewed ads and sales, or perhaps the number of times I refresh my blog and the non-changing page view count.
More details? Sure, but I need to define some terms. I’ll use friendly bold headings along the way.
Independent and dependant variables
The dependant variable is the thing that may depend on (be influenced by) the independent variable. Weight (dependent) may depend on height (independent). The two relationships can be swapped – height may depend on weight. Linear regression can examine both for you.
Further, regression attempts to estimate or predict, for each individual, the numerical value of some variable for that individual [1]. I, being almost six-foot tall could use linear regression to get an estimate of my weight based on data from others males my age. I’m taller than Jake Gyllenhaal, so I predict I weigh more than him.
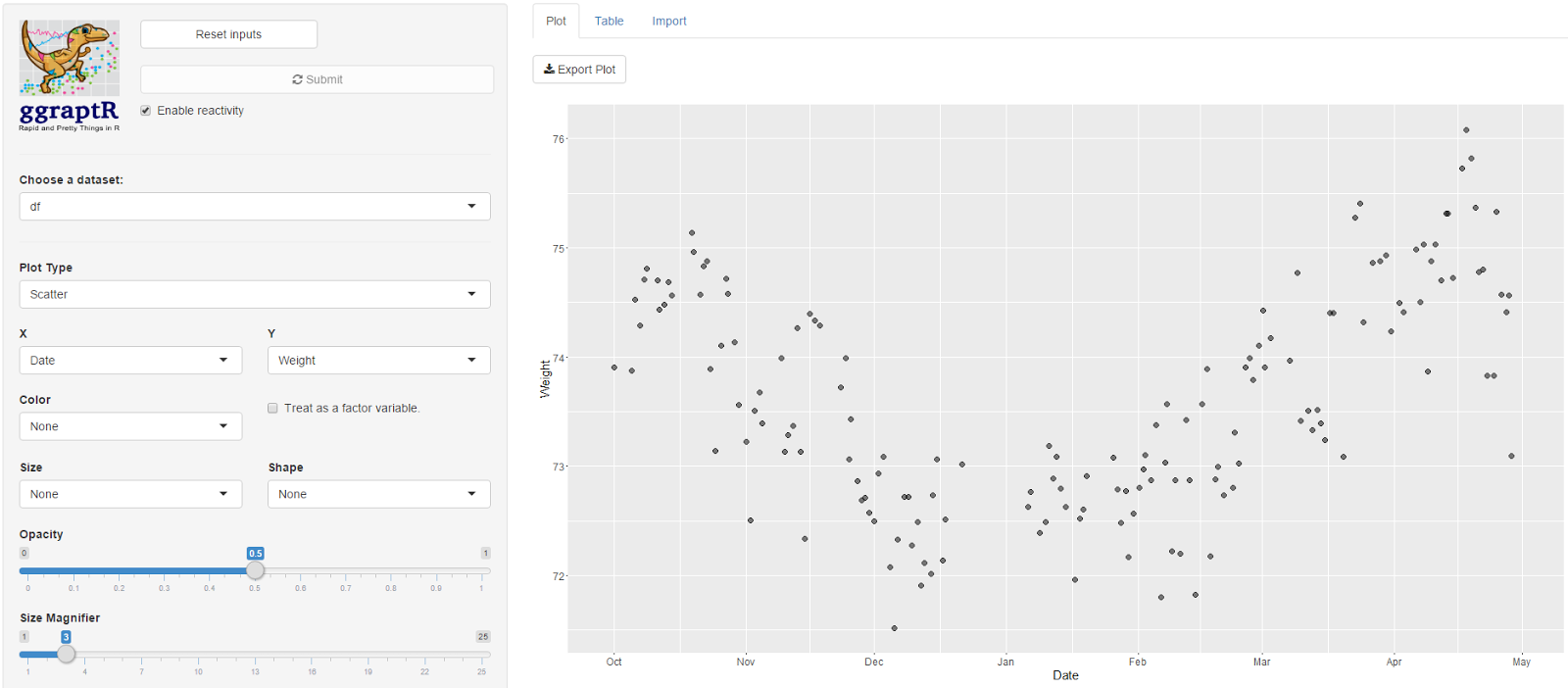
What about R-squared and interpreting coefficients? To answer, I need some diagrams. The following screengrabs are from an online course, “Data Science A-Z” at Super DataScience. In this simple linear regression example, the relationship between years of experience (x-axis) and salary (y-axis) is used.

Ordinary least squares and residual sum of squares
Linear regression will fit the “best” trendline through the data points as a model. Multiple trendlines can be produced through the data points. What occurs behind the scenes is an approach called “ordinary least squares”, which uses the distance between each data point to each examined trendline (see the next image). The distances are squared then summed, returning a value called the “residual sum of squares” for each fitted trendline (model). The best fitting line has the smallest residual sum of squares, that is, the smaller error out of all trendlines – the one that fits the data best.

Coefficients and unit change
In this simple linear regression example the model (best fitting trendline) can be described by the below equation. y is expected salary. x1 is the years of experience. b0 is a constant and equal to 30k in this model because, when years of experience (x1) is zero, salary (y) becomes equal to the constant b0. The image below shows that when years of experience is zero, the expected salary is 30k (circled in red). When I was a student on a Government PhD scholarship, it averaged 20k tax-free annually. This information is not relevant to linear regression. It’s simply a fun fact (about me, so it’s fun).
The coefficient b1 describes how a unit change in x1 effects y. At school, we called it the slope. In this example, the slope is equal to 10k (green arrows and projected dashes below). A unit change in experience (one year) will result in a 10k change (increase) in salary.


For multiple linear regression, there are more independent variables (x1, x2, x3, etc) and each has it’s own coefficient (b1, b2, b3, respectively). I’m not going to showcase an example of multiple linear regression here. Coefficients are the multipliers of each independent variable. Coefficients indicate how much the dependent variable (eg. salary) is expected to increase by one independent variable (eg. years of experience) holding all other independent variables constant (such as other related variables of interest if we had the data including years of education, gender, age, etc) [2].
I hope that answers what a coefficient is, at least in this simple linear regression example.
R-squared
We can work out a measure of the total sum of squares using the average trendline similar to deriving the residual sum of squares above. For total sum of squares, the distance between the points to the average trendline (red dotted vertical lines shown below) are squared and summed.

Quick recap – we have the residual sum of squares (SSres) from the best-fitting model and now the total sum of squares (SStot) from the average model.
R-squared is 1 – SSres/SStot. Why? I’m not entirely sure, but I know what happens to R-squared when the residual sum-of-squares (SSres) changes.
R-squared indicates how close the data are to the fitted regression line, using the average of y (eg. salary) as a baseline model. Look again at the R-squared equation – as SSres gets smaller (smaller error), R-squared will increase. The ideal case is that the model has zero residual sum of squares, which will result in an R-squared of 1. An R-squared of 1 suggests a perfect correlation between the independent and dependent variables (eg. a perfect correlation between years of experience and salary). This does not happen in practice, but the closer the R-squared is to 1, the greater the likelihood of a relationship between the variables in the model.
References and notes
1. From “Data Science for Business” by Foster Provost and Tom Fawcett.
2. I confess, this line is mysterious - “holding all other independent variables constant”? The explanation of this goes beyond a simple description of linear regression. Future blog post.